Solving Paraulògic
Recently, a word game has become quite the sensation among people who speak Catalan: “Paraulògic”, as it is called, consists of 7 letters arranged in the following hexagonal beehive pattern.
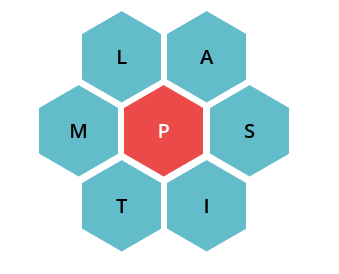
The objective is to from as many words as you can that contain the center letter (at least once) plus any number of the others. Furthermore, the exact set of letters changes every 24h, so a curious phenomenon occurs where people try to beat their real life peers by getting more words-of-the-day. This is actually an interesting game design choice.
Because Catalan comes from Latin (unlike English, that comes from barbarians), we use accents. Regardless, these are omitted in Paraulògic, the same happening with other marks such as apostrophes or hyphens.
If someone that reads this knows a version of this game in English, please send me an email so I can check it out.
Now that you get the hang of it, I’ll get to the point of this article: as the title surmises, I want to solve Paraulògic programatically. Even though I’m keen on words and solving puzzles, the prospect of solving infinitely many puzzles with one stroke doubly motivates me.
Approach
- Get all the words in my language (Catalan) into a single file that contains this dictionary.
- Read the dictionary and input letters of choice.
- Search for words that fit the criteria.
- Print these words in order of longest to shortest (longer words provide more points so it’s best to input them first).
1. Gather the armies (aka, words)
I’ll make a separate blogpost detailing the process (not unlike a tutorial) next week. Until then, here’s the TL;DR: We extract the dictionary from Libreoffice and parse all the words using Python. *Do not use this for comercial purposes, as it would infringe the GPL license
I saved the Python list into a file called “ca_netejat.txt” ready for use in my C++ script.
2. Read a file in C++, and read letters
To interact wih C++ using the terminal, the <iostream> library is very useful:
it allows for reading inputs (and through Bash piping, reading whole files) together with printing results to terminal.
Nonetheless, due to the nature of this problem, I would need 2 streams:
- One that reads the dictionary.
- Another that reads any number of 7 letter sequences (the first letter being the central one).
For that, I needed to use another library called <fstream> that allows me to do this:
#include <fstream>
using namespace std;
// Pre: File
// Post: Vector that contains all the words in a file separated by spaces.
vector<string> read(string file_name) {
fstream file;
file.open(file_name.c_str(), ios::in);
vector<string> s;
if (!file) {
cout << "No s'ha trobat el fitxer" << endl;
} else {
string w;
while (file >> w) s.push_back(w);
}
file.close();
return s;
}Reading the letters is easy as well:
const string DICT = "ca_netejat.txt";
int main() {
vector<string> dict = read(DICT);
cout << "Letters: ";
string chars;
while (cin >> chars) {
cout << "Solutions: ";
print(solver(dict, chars, chars[0]));
cout << "Letters: ";
};
}You’ll notice that I’ve called function that have yet to exist: solver(dict, chars, chars[0]) and print().
This is common practice for programmers, breaking down a problem into smaller bits and working on them separately.
In this case, I call the solver() function with all the information it needs:
a dictionary containing all the words in the corresponding language, a string containing all 7 chars (note that a string in C++ is almost identical to a vector<chars> and I could have used that instead) plus the special character that must be present in every word.
3. Implementing the Search algorithm
At first I thought I would need something fancy for this one. As it turns out, actually no: under the reasonable assumption that your dictionary is < 200.000 words, an O(n^2) is perfectly reasonable to work with. In all my tests, the following implementation is practically instantaneous:
#include <algorithm>
// Pre: String w and char c
// Post: Returns true if string w contains letter c.
bool contains(const string w, const char c) {
int n = w.size();
int i = 0;
while (w[i] != c and i < n) ++i;
return i != n;
}
// Pre: Two strings a, b
// Post: Returns true if string a should go before string b.
bool cmp(string a, string b) {
return a.size() > b.size() or (a.size() == b.size() and a < b);
}
// Pre: Dictionary dict, set of letters chars and central letter c
// Post: Returns a vector that contains all the words that are a solution
// ordered by size and alphabetically.
vector<string> solver(const vector<string> &dict, string chars, char c) {
vector<string> sol;
int n = dict.size();
for (int i = 0; i < n; ++i) {
if (contains(dict[i], c)) {
int m = dict[i].size();
int j = 0;
while (j < m and contains(chars, dict[i][j])) ++j;
if (j == m) {
sol.push_back(dict[i]);
}
}
}
sort(sol.begin(), sol.end(), cmp);
return sol;
}An important thing to note is the use of the sort() function from the <algorithm> library.
It implements a very powerful sorting algorithm called quicksort.
I’d very much like to write an article on this one in the future: algorithms are exciting creatures, you know?
4. Printing the words:
I already hinted at how to do this using the print function. Here’s how I’ve implemented it:
// Pre: Vector that contains any number of strings.
// Post: Print all the elements of the vector separated by a `,`.
void print(const vector<string> &words) {
int n = words.size();
cout << "There are " << n << " words: " << endl;
for (int i = 0; i < n; ++i) cout << i + 1 << ". " << words[i] << endl;
}Closing thoughts
This is it! This concludes my blog post on how to solve Paraulògic. I’ve already tried this strategy and reached the highest level in the game, signified by an 🦉.
You can find all the updated code in this github repository. Admittedly, I don’t deserve this owl for my linguistic efforts, but if it were to get some cool sunglasses and a laptop, I would be glad to accept it as my coder owl.